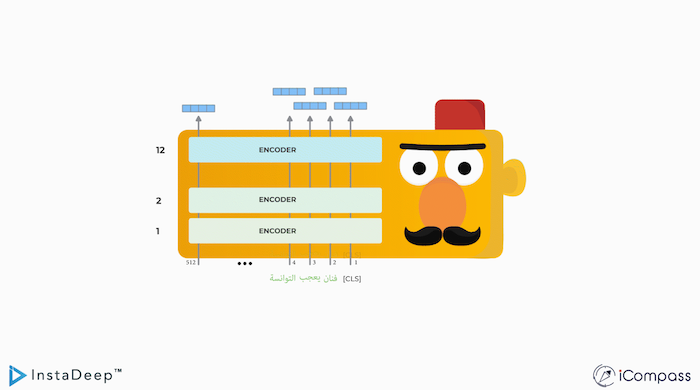
InstaDeep et iCompass ont annoncé que les deux startups spécialisées en IA offriraient TunBERT, le premier modèle de traitement du langage naturel (NLP) au monde pour le dialecte tunisien, gratuitement et en open source pour stimuler davantage l’innovation dans un écosystème de technologie AI Tunisien en pleine croissance. Cet écosystème est devenu un phénomène économique et technologique en Afrique du Nord au cours de la dernière décennie. TunBERT est un modèle linguistique pour le dialecte tunisien qui, en appliquant les dernières avancées en matière d’intelligence artificielle (IA) et d’apprentissage automatique (ML), a été entraîné pour évaluer plusieurs tâches telles que l’analyse des sentiments, la classification des dialectes et les questions-réponses pour la compréhension écrite.
En rendant TunBERT disponible gratuitement à l’écosystème, InstaDeep et iCompass visent à ouvrir la voie à de nouvelles percées en recherche et développement sur multiples secteurs, accélérant ainsi l’innovation en fournissant une base sur laquelle d’autres peuvent s’appuyer pour construire des applications sur tous les domaine d’expertise.
“Nous sommes ravis de dévoiler TunBERT, un projet de recherche né d’une collaboration étroite entre iCompass et InstaDeep qui offre au dialecte tunisien une technologie de pointe. Ce travail illustre également le niveau d’excellence auquel peut aspirer l’écosystème technologique tunisien grâce à des collaborations entre les startups leaders en IA”, dit Karim Beguir, PDG et cofondateur d’InstaDeep.
Surmonter les variations dialectales et la mauvaise interprétation
« Nous sommes ravis de mettre nos résultats à la disposition de la communauté au sens large sachant que très peu de recherches ont été effectuées sur les langues sous-représentées dans le passé. Notamment, la mauvaise interprétation des variations dialectales représente un grand défi aujourd’hui puisque l’arabe parlé compte une large variété de dialectes régionaux, ce qui rend la NLP pour les dialectes particulièrement difficile, et il en va de même pour la langue tunisienne », explique Dr Hatem Haddad, CTO et Cofondateur d’iCompass.
Améliorer la diversité et assurer une meilleure représentation pour tous les peuples – et leur langues – est critique pour développer équitablement l’intelligence artificielle dans le futur.
TunBERT a suscité beaucoup d’intérêt à travers la Tunisie et au-delà depuis qu’InstaDeep et iCompass ont annoncé leur collaboration. En effet, le résultat de cet effort a été dévoilé lors d’une session dédiée co-présentée par Hatem Haddad, Cofondateur et CTO d’iCompass, et Nourchene Ferchichi, ingénieur IA chez InstaDeep, lors de la GPU Technology Conference (GTC) de NVIDIA en avril.
Parlé par 12 millions de personnes, le dialecte Tunisien est étroitement lié aux dialectes nord-africains qui sont parlés par environ 105 millions de personnes. Le plus grand défi en ce qui concerne le dialecte tunisien est qu’il s’agit d’une langue non standard car elle n’a pas de règles grammaticales. Le Tunisien est également considéré comme une langue sous-financée par rapport à d’autres langues (par exemple l’anglais), en raison de la rareté des bases de données publiques en dialecte Tunisien. Avec de nombreuses variations et interprétations, la traduction linguistique peut facilement être mal comprise et créer des réactions négatives de la part des autres arabophones.
Communiqué